By: Charbel El-Khaissi
I took Lancaster University’s free Corpus Linguistics course (Corpus MOOC) to fill time. Three months later, a doctoral research proposal enabled by #LancsBox, a software tool introduced in the course, was accepted at the Australian National University.
For as long as this topic has been studied, ancient Semitic languages have relied on classical philological approaches. Naturally, a tension exists between this tradition and contemporary approaches in computational linguistics. It would be unfair to characterise this divide as a mere consequence of ‘old-school’ scholars resisting technological changes in research because philology is an inherent part of the study. The study of any ancient language requires far more human involvement than a machine can achieve: a careful hand to conserve and restore manuscripts, a keen eye for epigraphic analysis and a well-rounded, learned mind to interpret literature in medias res, politically, theologically and societally. However, as far as the researcher is open to computer-assistive technology, #LancsBox fills a much-needed gap in historical linguistics, especially in the field of Semitic historical syntax.
As a case in point, consider the Aramaic language: the longest, continuously spoken Semitic language with an attested lifespan of approximately 3,000 years. This human language offers linguists intriguing insights on how human languages change over a substantial time period, including changes in its underlying structure (i.e., grammar and syntax). If these changes are substantiated then their insights may lend important cues concerning the evolution of human cognition itself. Yet, the historical syntax of Aramaic remains largely underrepresented and understudied. Few commendable scholars have undertaken the task of analysing developments in areas of Aramaic grammar (e.g., Huehnergard, 2005; Rubin, 2005; Grassi, 2009; Pat-El, 2012; Coghill, 2012). Among other reasons, the lack of rigorous study in this discipline is due to the labour-intensive task of qualitatively analysing large corpora. This task is made more difficult by a manual transcription and grammatical tagging process, in addition to administration duties such as record management and categorisation. Recent advancements in Aramaic computational linguistics – including, but not limited to Handwriting-text Recognition (HTR) technology and digital archives – have significantly reduced time of text transcription and tagging. However, the diachronic analysis of large corpora remains tedious without a free, user-friendly and accessible corpus software like #LancsBox.
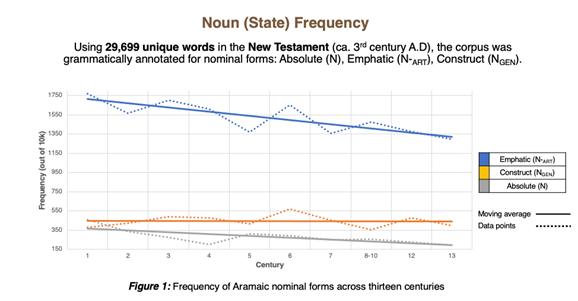
My doctoral research is among the first studies in Semitic historical linguistics to experiment with Lancaster University’s #LancsBox corpus software and analyse Aramaic syntax over time. Thus far, it has proven to be an exceptional tool for data management and diachronic analysis (see Figure 1 and Figure 2):
• Corpus management: the ease of creating, storing and analysing (sub-)corpora based on variables of interest (e.g., by dialect, century, author) reduces administrative overhead and gives me more time test different hypotheses according to multiple variables.
• POS-tagging: in addition to offering POS tagging in a number of languages, #LancsBox caters to self-tagged corpora. This means I can import datasets that have been annotated according to my own tagging scheme, which gives me flexibility when testing the robustness of tag sets according to various theoretical frameworks.
As with any computer software, few caveats are worthy of mention to historical Semitic linguists interested in using the software for their research.
• Coding: basic knowledge of Regular Expression coding is needed to execute meaningful, in-context searches.
• Font: in its current version (5.0), Aramaic is partially-supported, with some fonts appearing disconnected. This makes in-tool legibility difficult, but not impossible.
• Text-direction: in its current version (5.0), Aramaic texts appear reversed (e.g., “cat” appears “tac”). Current workarounds include (1) using free, online tools to reverse the text prior to import, or (2) conducting analysis outside the tool.
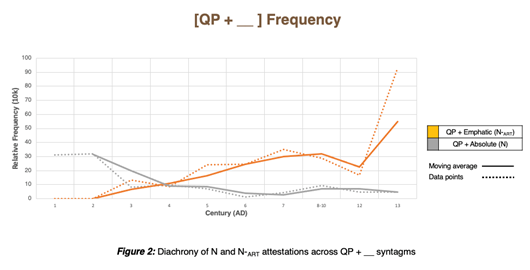
Will #LancsBox become the MO for future historical linguists? Only time will tell. It seems to me the only accessible software currently available for linguists who wish to build and design their own corpus, especially in underrepresented and under resourced languages. In fact, I can think of a number of innovative applications outside the research domain as well: for example, Australian linguists might be able to use #LancsBox to investigate which linguistic features have been declining in student writing over the last decade. Perhaps then #LancsBox’s core functionalities could help academics in other fields and a wider group of users.
Watch a 60-second video of Charbel El-Khaissi’s research here.
Acknowledgements: Thank you Professor Tony McEnery, Dr Pierre Weill-Tessier and Dr Vaclav Brezina whose innovations have enabled my research. I express gratitude to my supervisory panel for their ongoing guidance.