CASS is committed to advancing corpus linguistics through innovation. We actively seek opportunities to pioneer new techniques in corpus analysis and apply them across social science and the digital humanities. This effort is underpinned by our theoretical research (e.g. McEnery & Brezina, 2022) and practical expertise gained through our extensive portfolio of research projects.
#LancsBox X, CASS’s flagship software tool available for free, reflects the most recent developments in the field and offers its users a comprehensive solution for the analysis of language data. The newly released version, #LancsBox X 4.0.0, introduces a range of innovative features, positioning the tool as one of the most powerful options available with analytical capabilities unparalleled elsewhere. So, what are the innovations in v. 4.0.0?
N-grams and skip-grams
In the Words tool, users can now compute n-grams (continuous sequences of words) and skip-grams (fixed-length sequences of words with wildcard elements). They can select from simple drop-down menus to choose the size of the word sequence e.g. 2-gram, 3-gram, 4-gram etc. and the unit such as word, headword, lemma, lexeme, pos tag, semantic tag etc. The results can be queried and filtered according to different criteria. For example, users can identify all sequences including the word ‘new’ anywhere in the n-gram/skip-gram or filter for all sequences that start with the word ‘new.’
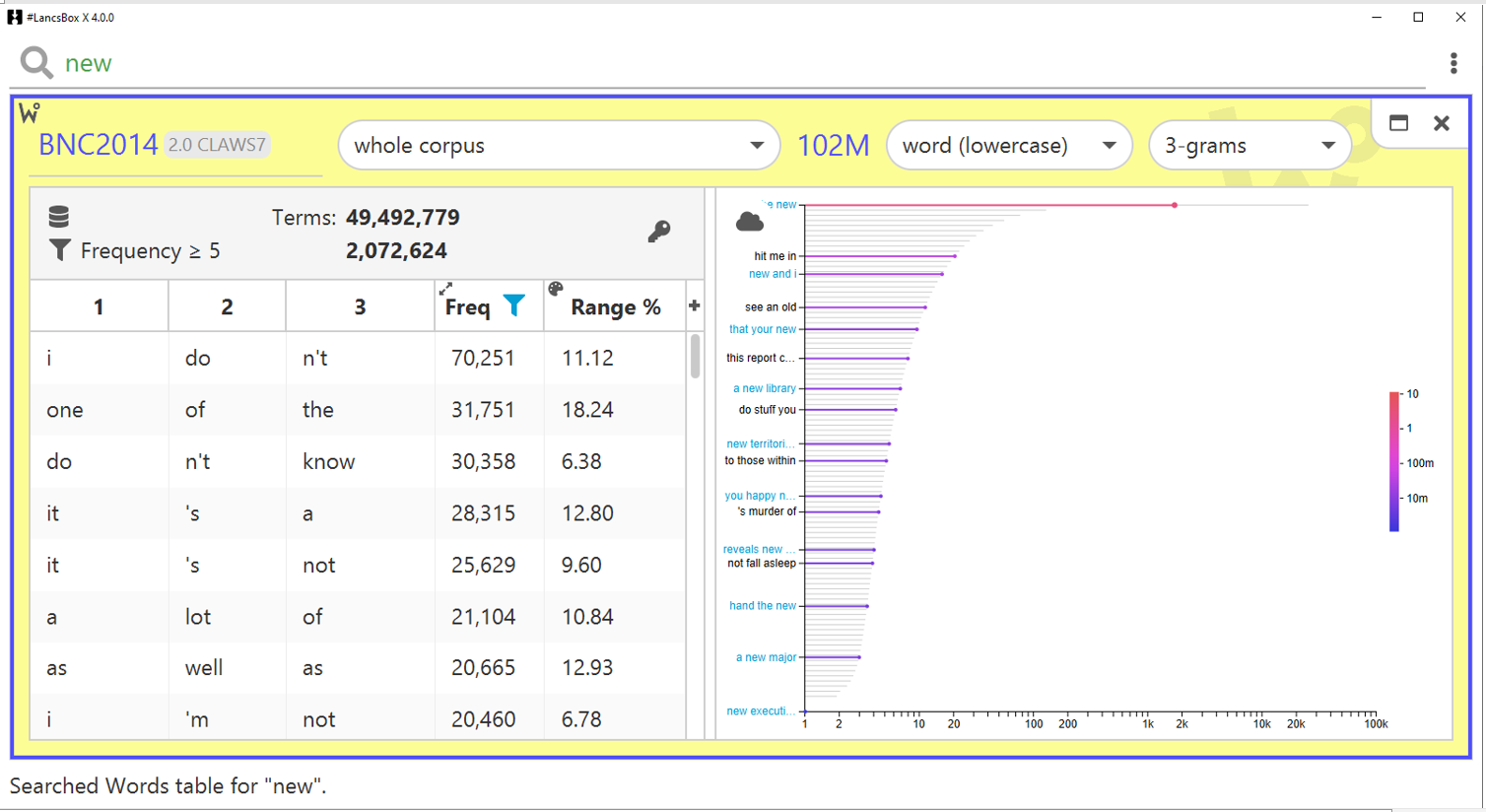
Figure 1. 3-grams in the BNC2014
For large corpora such as the BNC2014, we have pre-computed n-grams for the ease of use. Users who have already downloaded older versions of the corpus are advised to delete BNC2014 and download it again.
N-grams and skip-grams for user corpora are computed and stored for later use. For smaller corpora, this may take several minutes, for very large corpora up to several hours. Once the process is completed, the information is immediately accessible.
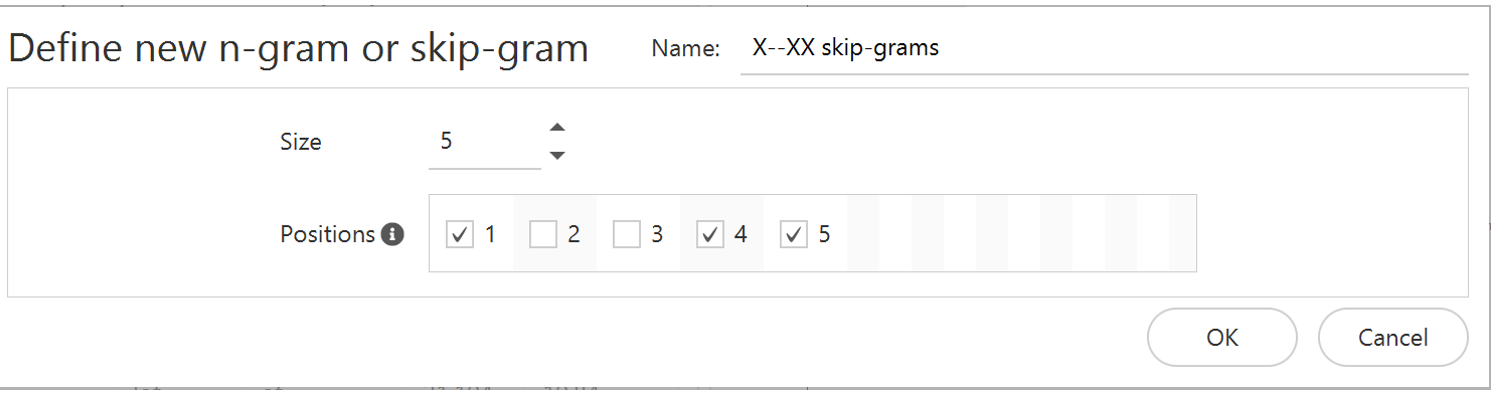
Figure 2. Defining a skip-gram
Exporting corpora
Users can also tag and export their corpora. #LancsBox X allows automatic lemmatization and tagging of corpora for part-of-speech, syntactic dependency and semantic category. This functionality is available for all major languages, such as English, Spanish, Chinese etc. Corpora are exported as xml documents.

Figure 3. Exporting a tagged corpus as an xml document
Word clouds
Whether you’re a fan or a critic, word clouds provide an attractive method for visualizing word frequencies within a dataset. However, traditional word clouds suffer from a lack of depth (arbitrary colour assignment, position of words without a specific meaning), often leading to misinterpretation. In contrast, #LancsBox X revolutionizes this approach by offering a more informative and linguistically meaningful representation. By considering various properties of words, including frequency and dispersion, #LancsBox X generates word clouds that convey key statistical values. Font size, font colour, and word positioning dynamically reflect these properties, providing a richer and more accurate visualization of the underlying data.
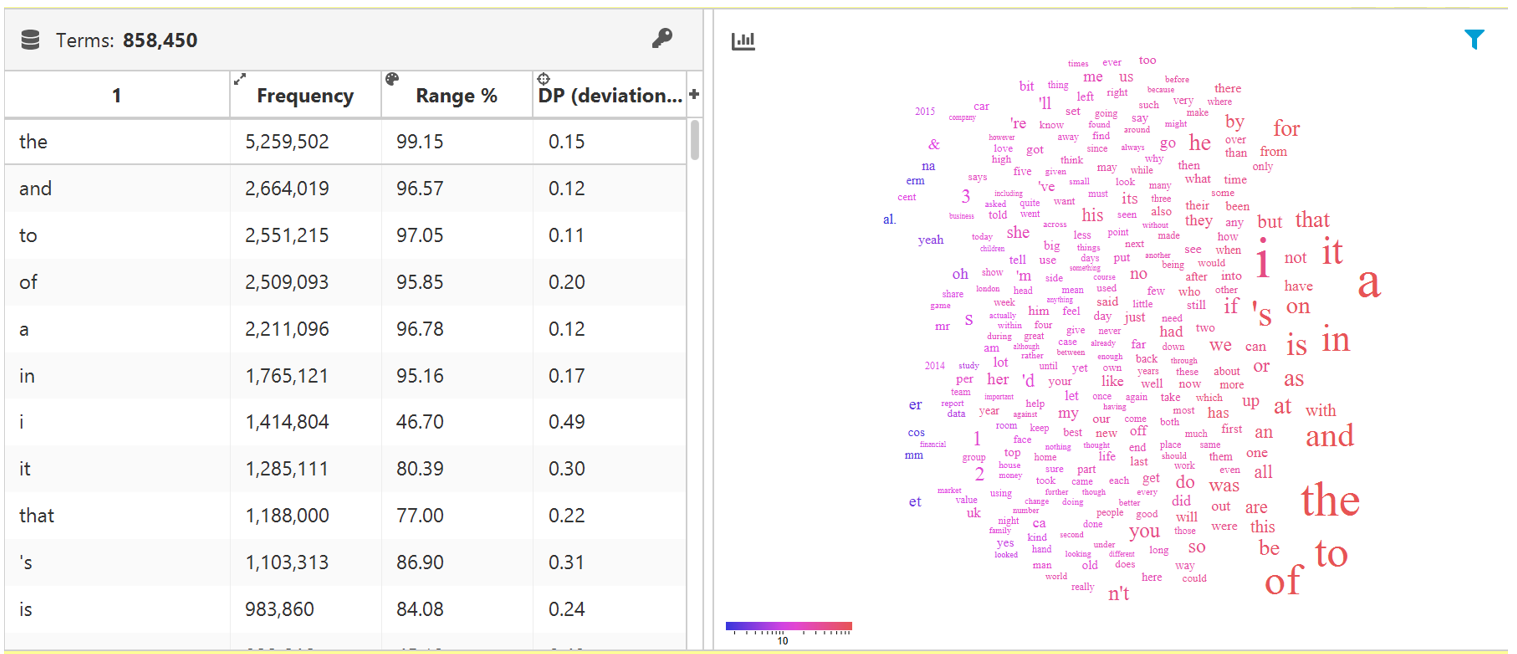
Figure 4. A word cloud in #LancsBox X
Lightning fast searching
How swiftly can you determine the frequency of the given complex structure in a corpus containing 100 million words: ADJECTIVE NOUN VERB ADVERB? When employing #LancsBox X on a typical desktop or laptop, you’ll receive the answer in just about 18 seconds. Comparatively simpler queries such as ‘my,’ ‘news,’ or ‘person’ in the same dataset of 100 million words take less than a second to process. Furthermore, you’ll obtain a complete set of results that are sortable and filterable to meet your requirements. Additionally, you’ll avoid wasting time deciphering the exact part-of-speech tags for e.g. adjectives (which are tagged as ‘JJ’!) or nouns, as #LancsBox X streamlines the search process by accepting intuitive categories like ADJECTIVE, PASSIVE, or PEOPLE for efficient querying.
You can download #LancsBox X for free from https://lancsbox.lancs.ac.uk. The website also includes video tutorials, exercises and a manual.