 It has been little over a year since CASS and Cambridge University Press announced a collaboration to compile a successor to the spoken component of the British National Corpus, the Spoken BNC2014. This will be the largest corpus of spoken British English since the original, with the advantage of being collected in the 2010s rather than the 1990s, providing an updated snapshot of spoken language in the UK. By including a set of recordings already gathered by Cambridge University Press before our collaboration began, we plan for the corpus to contain data ranging from the years 2012-2016. As well as being the year in which the project was announced, 2014 will be the median year of the planned data range, and so we chose it to feature in the working title of the project: the Spoken BNC2014.
It has been little over a year since CASS and Cambridge University Press announced a collaboration to compile a successor to the spoken component of the British National Corpus, the Spoken BNC2014. This will be the largest corpus of spoken British English since the original, with the advantage of being collected in the 2010s rather than the 1990s, providing an updated snapshot of spoken language in the UK. By including a set of recordings already gathered by Cambridge University Press before our collaboration began, we plan for the corpus to contain data ranging from the years 2012-2016. As well as being the year in which the project was announced, 2014 will be the median year of the planned data range, and so we chose it to feature in the working title of the project: the Spoken BNC2014.
Since our announcement, we have been hard at work: advertising the project nationally, collecting recordings from speakers from all over the UK, transcribing the data, conducting methodological investigations, and presenting our work so far at corpus linguistics conferences. At ICAME 36 in May we described the development of the Spoken BNC2014 transcription scheme, and at Corpus Linguistics 2015 in July we gave an overview of the data collection methodology as well as presenting new research on speaker identification in transcription. All of this activity continues as we work towards making the corpus freely and publicly available in the year 2017.
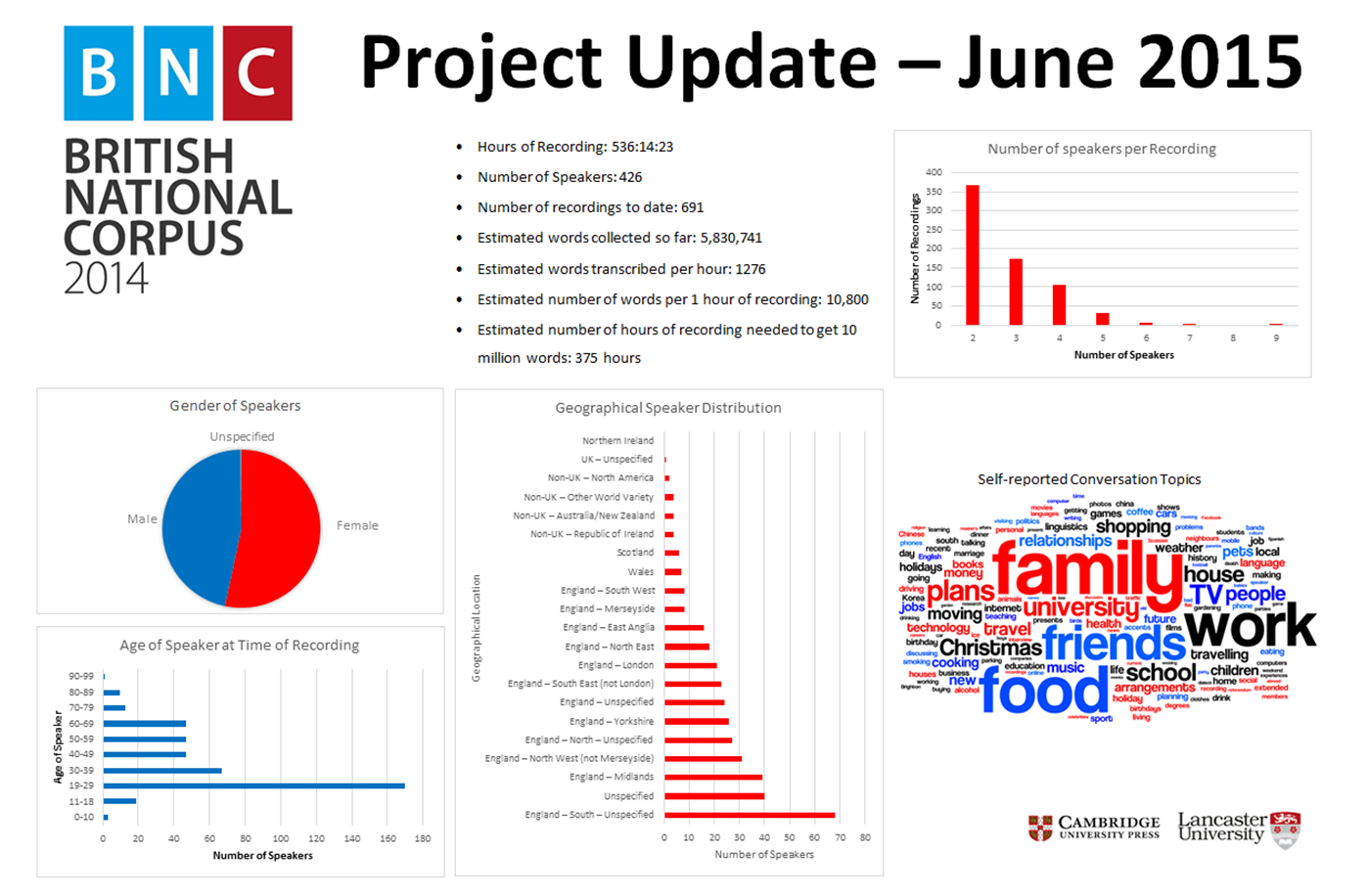
So far, we have gathered nearly 700 recordings at an estimated total of approximately six million words of informal conversational data. The majority of recordings feature two or three speakers, with about a quarter of recordings containing four or more so far. So far, the balance of speaker gender is fairly even, and we have been able to gather data from a wide range of ages – though at the moment the 19-29 year olds have a clear lead! We have done very well in England to gather recordings from a great range of self-reported dialects, and we plan now to focus more heavily on gathering recordings from Wales, Scotland, and Northern Ireland. The word cloud of self-reported conversation topics gives a first look at the range of things that users can expect to find being discussed in the corpus.
We are very pleased with the progress of the project so far, and we look forward to releasing the corpus texts publicly once they are complete. In the meantime, as announced at CL2015, we will be offering the opportunity to apply for pre-release data grants later this year. More information about the data grants will be announced in the near future.