![]() How wonderful it is to get to the inner workings of the creature you helped bring to life! I’ve just spent a week with the wonderful – and superbly helpful – team at CASS devoting time to matters on the Trinity Lancaster Spoken Corpus.
How wonderful it is to get to the inner workings of the creature you helped bring to life! I’ve just spent a week with the wonderful – and superbly helpful – team at CASS devoting time to matters on the Trinity Lancaster Spoken Corpus.
Normally I work from London situated in the very 21st century environment of the web – I plan, discuss and investigate the corpus across the ether with my colleagues in Lancaster. They regularly visit us with updates but the whole ‘system’ – our raison d’etre if you like – sits inside a computer. This, of course, does make for very modern research and allows a much wider circle of access and collaboration. But there is nothing like sitting in the same room as colleagues, especially over the period of a few days, to test ideas, to leap connections and to get the neural pathways really firing.

It’s been a stimulating week not least because we started with the wonderful GraphColl, a new collocation tool which allows the corpus to come to life before our eyes. As the ‘bubbles’ of lexis chase across the screen searching for their partners, they pulse and bounce. Touching one of them lights up more collocations, revealing the mystery of communication. Getting the number right turns out to be critical in producing meaningful data that we can actually read – too loose and we end up with a density we cannot untangle; the less the better seems to be the key. It did occur to me that finally language had produced something that could contribute to the Science Picture Library https://www.sciencephoto.com/ where GraphColl images could complement the shots of language activity in the brain. I’ve been experimenting with it this week – digging out question words from part of the corpus to find out how patterned they are – more to come.
We’ve also been able to put more flesh on the bones of an important project developed by Vaclav Brezina – how to make the corpus meaningful for teachers (and students). Although we live in an era where the public benefit of science is rightly foregrounded, it can be hard sometimes to ‘translate’ the science and complexity of the supporting technology so that it is of real value to the very people who created the corpus. Vaclav has been preparing a series of extracts of corpus data that can come full circle back into the classroom by showing teachers and their students the way that language works – not in the textbooks but in real ‘lingua franca’ life. In other words, demonstrating the language that successful learners use to communicate in global contexts. This is going to be turned into a series of teaching materials with the quality and relevance being assured by crowdsourcing teaching activities from the teachers themselves.
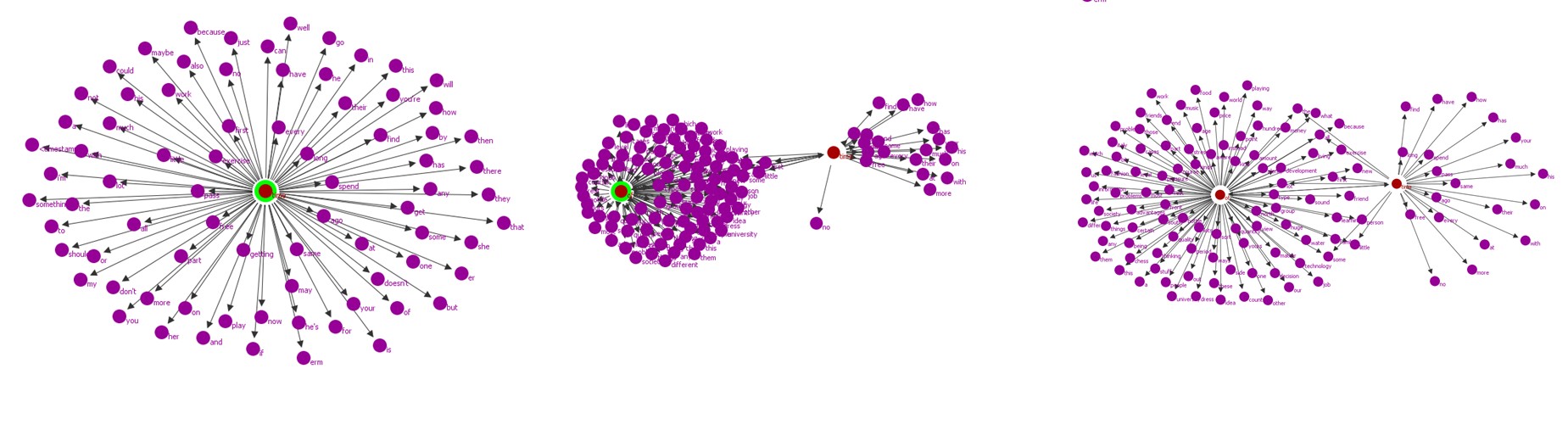 Collocates of time in the GESE interactive task
Collocates of time in the GESE interactive task
Meanwhile I am impressed by how far the corpus – this big data – is able to support Trinity by helping to build robust validity arguments for the GESE test. This is critical in helping Trinity’s core audience – our test takers – to understand why should I do this test, what will the test demonstrate, what effect will it have on my learning, is it fair? All in all a very productive week.