The version of the EEBO-TCP data that has been available on Lancaster University’s CQPweb server is now rather old (the TCP project adds text to the collection on a rolling basis), and, more importantly, does not contain any annotations. Recently I have devoted some time to running a newer version through UCREL’s standard annotation tools and then mounting the resulting dataset on CQPweb. The new version stands at 1.2 billion running tokens, each with eight different annotation fields.
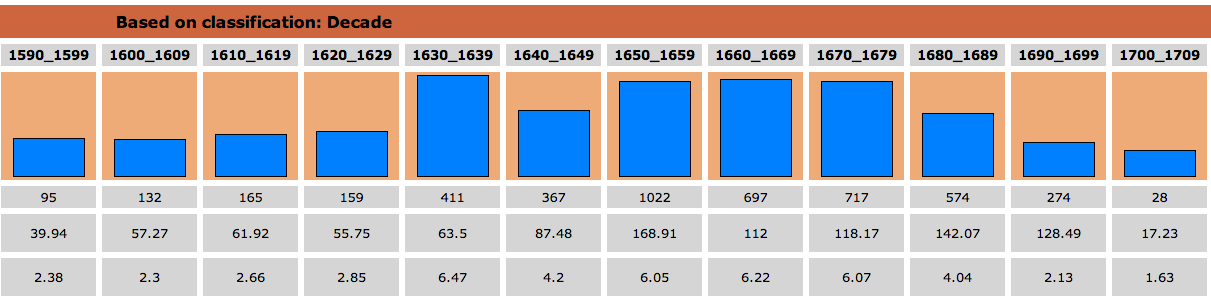
Critically, the first layer of annotation is spelling regularisation, which means that the accuracy of the subsequent layers including part-of-speech tagging and lemmatisation is enhanced. Regularised spelling means that searches can be much more comprehensive. Once I had finished with the indexing process, one of the first searches that Paul Rayson did (in preparation for a presentation at the EEBO-TCP conference in Oxford this week) was to check on the word experiment and to compare the results returned by a search on original spelling as compared to regularised spelling.
![]()
![]()
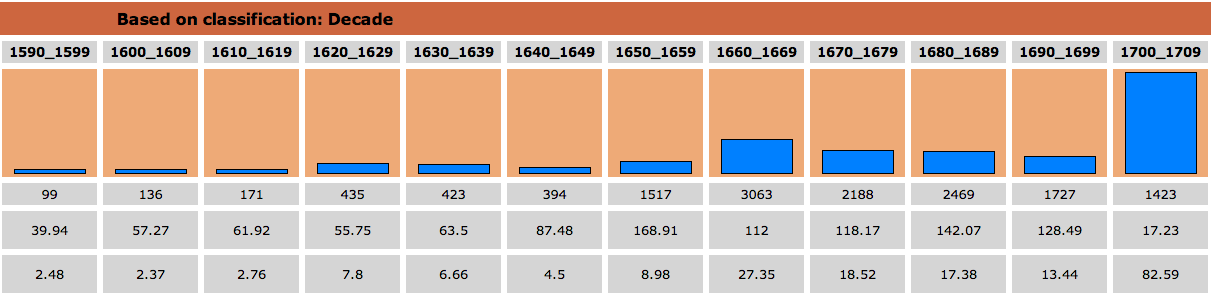
The version with regularised spelling (the second graph) returns about three times as many results as the version without (the first graph). The distribution is also rather different. As the following graph shows, the use of a lemma search retrieves even more relevant examples:
![]()
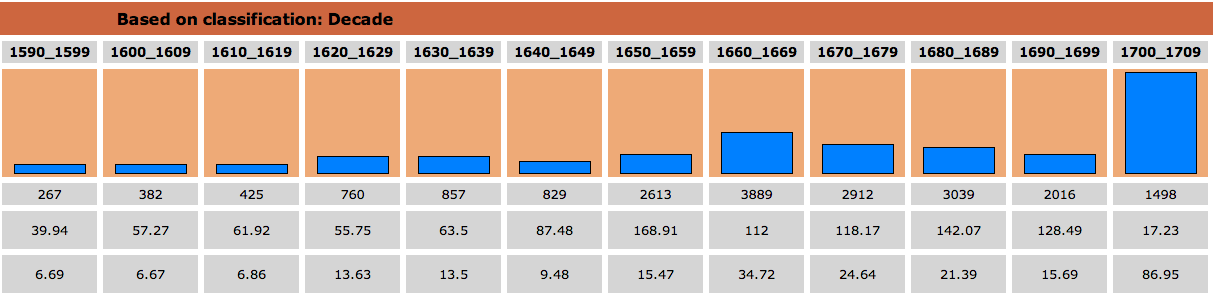
This illustrates the value of the standard annotations to the analysis of the EEBO-TCP data. The newly indexed corpus will be of use both for CASS purposes and for the CREME research group.