The BBC’s multilingual NewsHACK event was run on the 15th and 16th of March as an opportunity for teams of language technology researchers to work with multilingual data from the BBC’s connected studio. The theme was ‘multilingual journalism: tools for future news’, and teams were encouraged to bring some existing language technologies to apply to problems in this area. Nine teams attended from various news and research organisations. Lancaster University sent two teams with funding from CASS, CorCenCC, DSI, and UCREL: team ‘1’ consisting of Paul, Scott and Hugo, and team ‘A’ comprising Matt, Mahmoud, Andrew and Steve.

The brief from the newsHACK team suggested two possible directions: to provide a tool for the BBC’s journalist staff, or to create an audience-facing utility. To support us, the BBC provided access to a variety of APIs, but the Lancaster ‘A’ team were most interested to discover that something we’d thought would be available wasn’t — there is no service mapping news stories to their counterparts in other languages. We decided to remedy that.
The BBC is a major content creator, perhaps one of the largest multilingual media organisations in the world. This presents a great opportunity. Certain events are likely to be covered in every language the BBC publishes in, providing ‘translations’ of the news which are not merely literal translations at the word, sentence or paragraph level, but full-fledged contextual translations which identify the culturally appropriate ways to convey the same information. Linking these articles together could help the BBC create a deeply interesting multilingual resource for exploring questions about language, culture and journalism.
Interesting, but how do we make this into a tool for the BBC? Our idea was to take these linked articles directly to the users. Say you have a friend who would prefer to read the news in their native tongue — one different to your own — how would you share a story with them? Existing approaches seem to involve either using an external search engine (But then how do you know the results are what you intend to share, not speaking the target language?) or to use machine translation to offer your friend a barely-readable version of the exact article you have read. We came up with an idea that keeps content curation within the BBC and provides readers with easy-access to the existing high-quality translations being made by professional writers: a simple drop-down menu for articles which allows a user to ‘Read about this in…’ any of the BBC’s languages.

To implement this, in two days, required a bit of creative engineering. We wanted to connect articles based on their content, but we didn’t have tools to extract and compare features in all the BBC’s languages. Instead, we translated small amounts of text — article summaries and a few other pieces of information — into English, which has some of the best NLP tool support (and was the only language all of our team spoke). Then we could use powerful existing solutions to named entity recognition and part-of-speech tagging to extract informative features from articles, and compare them using a few tricks from record linkage literature. Of course, a lack of training data (and time to construct it!) meant that we couldn’t machine-learn our way to perfection for weighting these features, so a ‘human learning’ process was involved in manually tweaking the weights and thresholds until we got some nice-looking links between articles in different languages.
Data is only part of the battle, though. We needed a dazzling front-end to impress the judges. We used a number of off-the-shelf web frameworks to quickly develop a prototype, drawing upon the BBC’s design to create something that could conceivably be worked into a reader’s workflow: users enter a URL at the top and are shown results from all languages in a single dashboard, from which they can read or link to the original articles or their identified translations.
Here we have retrieved a similar article in Arabic, as well as two only-vaguely-similar ones in Portuguese and Spanish (the number indicates a percentage similarity). The original article text is reproduced, along with a translated English summary.
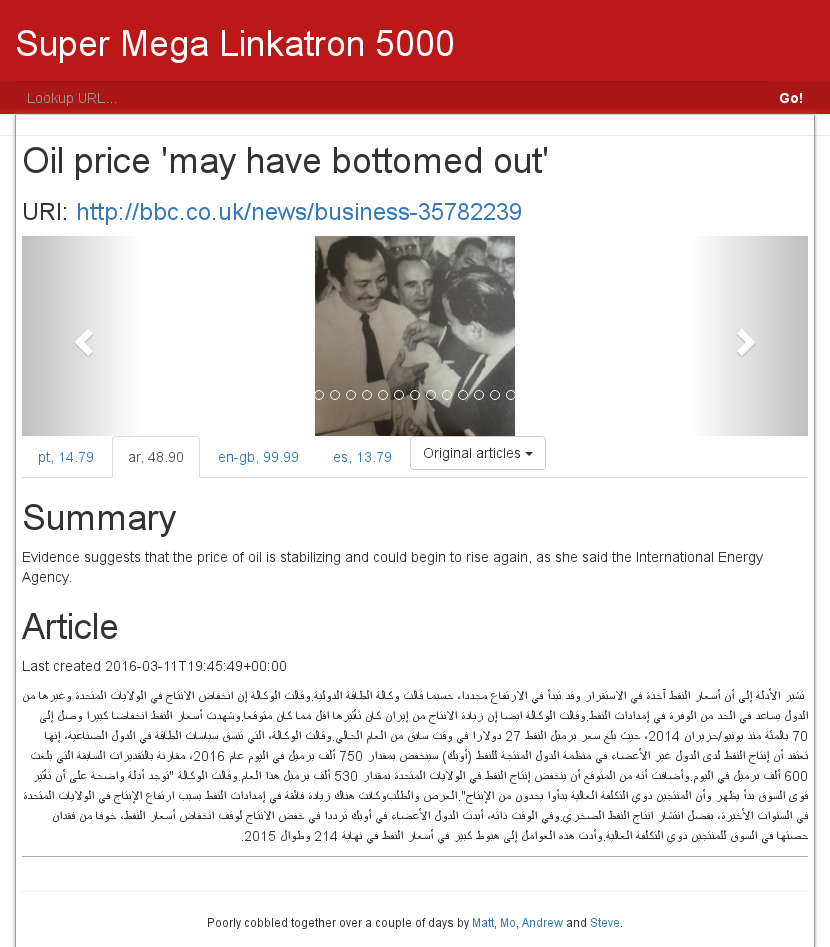
The judges were impressed — perhaps as much with our pun-filled presentation as our core concept — and our contribution, the spontaneously-titled ‘Super Mega Linkatron 5000’ was joint winner in the category of best audience-facing tool.
The BBC’s commitment to opening up their resources to outsiders seems to have paid off with a crop of high-quality concepts from all the competitors, and we’d like to thank them for the opportunity to attend (as well as the pastries!).
The code and presentation for the team ‘A’ entry is available via github at https://github.com/StephenWattam/LU-Newshack and images from Lancaster’s visit can be seen at https://flic.kr/s/aHskwHcpNH . Some of the team have also written their own blog posts on the subject: here’s Matt’s and Steve’s.
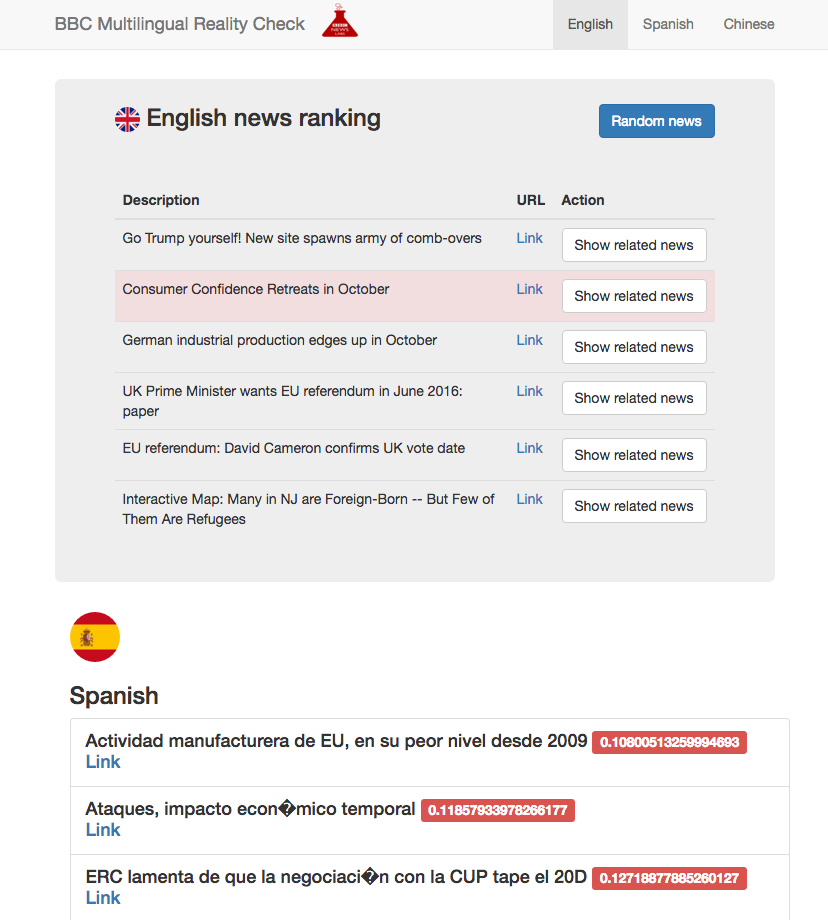
Team ‘1’ based their work around the BBC Reality Check service. This was part of the BBC News coverage of the 2015 UK general election and published news items on twitter and contributed to TV and radio news as well. For example, in May 2015 when a politician claimed that the number of GPs has declined under the coalition government, BBC Reality Check produced a summary of data obtained from a variety of sources to enable the audience to make up their own mind about this claim. Reality Check is continuing in 2016 with a similar service for the EU referendum, providing, for example, a check on how many new EU regulations there are every year (1,269 rather than the 2,500 claimed by Boris Johnson!!). After consulting with the BBC technology producer and journalist attending the newsHACK, Team ‘1’ realised that this current Reality Check service could only serve its purpose for English news stories, so set about making a new ‘BBC Multilingual Reality Check’ service to support journalists in their search for suitable sources. Having a multilingual system is really important for the EU referendum and other international news topics due to the potential sources being written in languages other than English.
In order to bridge related stories across different languages, we adopted the UCREL Semantic Analysis System (USAS) developed at Lancaster over the last 26 years. The system automatically assigns semantic fields (concepts or coarse-grained senses) to each word or phrase in a given text, and we reasoned that the frequency profile of these concepts would be similar for related stories even in different languages e.g. the semantic profile could help distinguish between news stories about finance or education or health. Using the APIs that the BBC newsHACK team provided, we gathered stories in English, Spanish and Chinese (the native languages spoken by team ‘1’). Each story was then processed through the USAS tagger and a frequency profile was generated. Using a cosine distance measure, we ranked related stories across languages. Although we only used the BBC multilingual news stories during the newsHACK event, it could be extended to ingest text from other sources e.g. UK Parliamentary Hansard and manifestos, proceedings of the European parliament and archives of speeches from politicians (before they are removed from political party websites).
The screenshot below shows our analysis focussed on some main topics of the day: UK and Catalonia referendums, economics, Donald Trump, and refugees. Journalists can click on news stories in the system and show related articles in the other languages, ranked by our distance measure (shown here in red).
Team ‘1’s Multilingual Reality Check system would not only allow fact checking such as the number of refugees and migrants over time entering the EU, but also allow journalists to observe different portrayals of the news about refugees and migrants in different countries.