Introduction
Corpus Linguistics 2015 – CL2015 – is the largest conference of its kind and this year drew over 250 attendees from all over the world to present work outlining the state of Corpus Linguistics (CL) at large, leading-edge technology and methods, and setting the agenda for years to come.
Of particular interest to me was a small but important streak of enquiry running through the conference, which is also becoming more prevalent in CL as a whole. That is, a focus on corpora collected from online source such as blogs and social media (Elgesem & Salway 2015; Grieve, et al. 2015; Hardaker & McGlashan 2015; Knight 2015; Longhi & Wigham 2015; McGlashan & Hardaker 2015; Statache, et al. 2015). The Internet now enables great opportunities for the collection and interrogation of large amounts of data – big data, even – and the rapid compilation of specialised corpora in ways previously impossible.
I focus here on social media data, specifically data collected from Twitter. Sampling data from Twitter, like a lot of other online sources, offers the opportunity to collect what people are saying (the content of their posts; tweets) but also a huge amount of metadata about the date, time, user, shared content (e.g. hyperlinks, retweets), interactional information, etc. relating to those posts. As Corpus Linguists, we therefore get the data we sample for – posts containing the thing(s) we are interested in – as well as other social information about the content creators and their social networks that we may or may not be interested in. Indeed, concerns about the kinds of metadata included and attached to online post is an issue that has sparked a great deal of debate about the ethics of collecting and using publicly posted online content, though these concerns are not discussed here. Instead, the potential for online ethnography is explored. In order to do this, I pair familiar CL research methods with methods from Social Network Analysis (SNA) that are more explicitly focussed on social networks and examining the myriad ways people affiliate with each other.
Theory & Methods: Corpus-assisted Community Analysis (CoCoA)
Corpus-assisted Community Analysis (CoCoA) is a multimethodological approach to the study of online discourse communities that combines methods from Discourse Analysis (DA), CL, and SNA.
Corpus-assisted Discourse Analysis
I predominantly draw on Baker (2006) in my approach to corpus-assisted DA, seeing discourse in a Foucauldian sense as, forms of social practice; “practices which systematically form the objects of which they speak” (Foucault 1972: 49). Particularly, I am interested in the incremental effect of discourse. Baker suggests, “a single word, phrase or grammatical construction on its own may suggest the existence of a discourse” (2006: 13). However, in order to investigate how quantitatively typical or pervasive discourse is within a discourse community, numerous examples of linguistic instantiations of discourse are required to make a claim about its cumulative effect (ibid.). Following Baker, I argue here that corpora and CL techniques enable this kind of quantitative examination of discourse.
Social Network Analysis
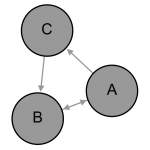
SNA implements notions from graph theory for the formal modelling and describing the properties of relationships between objects of study such as people and institutions. A graph (or ‘sociogram’) is a representation of people or institutions of interest as ‘nodes’ and the relationships between them as a set of lines known as ‘edges’; a graph is built by representing “a set of lines [‘edges’] connecting points [‘nodes’]” (Scott 2013: 17). To interpret graphs, graph theory contributes “a body of mathematical axioms and formulae that describe the properties of the patterns formed by the lines [‘edges’]” (Scott 2013: 17). One of these axioms is ‘directionality’. Directed graphs can encode both symmetric and asymmetric relations (D’Andrea, et al. 2010: 12). Directed relationships are where nodes are connected by an edge that has a direction of flow from one node to another is known as asymmetric, as illustrated by the relations between A and C, and C and B in Fig. 1. Symmetric relationships are those in which an edge connects two nodes but is bidirectional – the direction of relation flows both ways – as illustrated by the relationship between A and B in Fig. 1. Directed relationships on Twitter include followership relations and the act of mentioning – i.e. including the handle (e.g. @CorpusSocialSci) – in tweets.
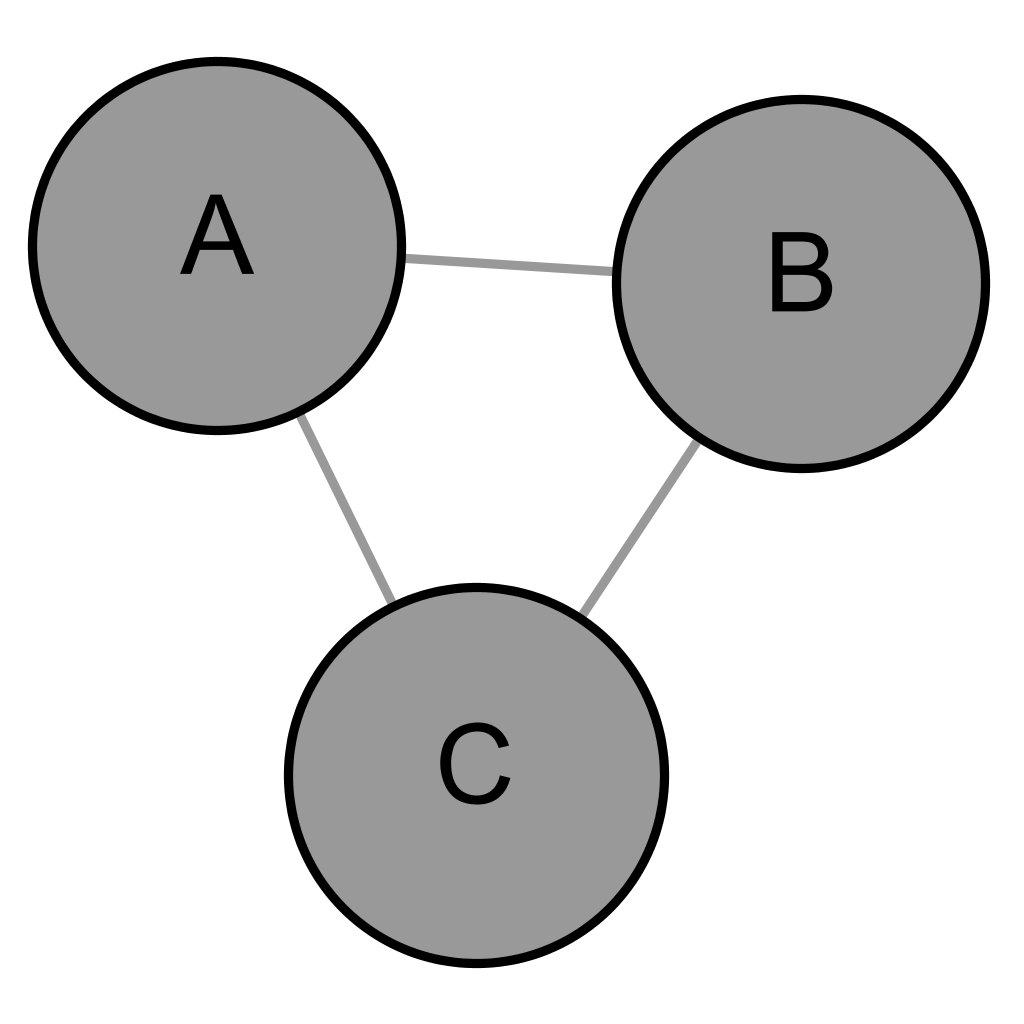
Undirected graphs represent identical, symmetric relationships between nodes which might be the result of nodes sharing reciprocal attitudes or “because they have a common involvement in the same activity” (Scott 2013: 17). Fig. 2 contains gives a graphical representation of an undirected graph.
Directed and undirected (‘ambient’) kinds of affiliation are both understood here as being distinct forms of discursively constructed social practices. Furthermore, I adopt the term ‘ambient affiliation’ from the work of Zappavigna on the use of social media in the formation of community and identity (Zappagigna 2012; Zappagigna 2013). Ambient affiliation is about the functionalities of social media platforms that enable users “to commune with others without necessarily engaging in direct conversational exchanges” (Zappagigna 2013: 223-4). Therefore, ambient affiliation is about people exhibiting the same behaviours or sharing the same qualities but without directly interacting with each other. This notion closely approximates to the notion of an ‘undirected’ graph. In developing the theory of ambient affiliation Zappavigna draws on Page’s work on hashtags. Page refers to hashtags as “a search term” (2012: 183). Hashtags – a string of characters (usually a word or short phrase) unbroken by spaces or non-alphabetic/non-numeric characters (excl. underscores ‘_’) preceded by ‘#’ (e.g. #YOLO) – are used a metadiscursive markers of the topic of a tweet. Page goes onto argue that, “the kind of talk which aggregate around hashtags […] involve multiple participants talking simultaneously about the same topic, rather than individuals necessarily talking with each other in dyadic exchanges that resemble a conversation” (2012: 196). As such, Page suggests that hashtags destabilise conventional adjacency pairs characteristic of many forms of human dialogue and give a new way for humans to interact on a topic of mutual interest.
Data
I collected all tweets and retweets including the official hashtag of the Corpus Linguistics 2015 conference – #CL2015 – posted from the date of the first pre-conference workshop (20/07/2015) through until the final day of the conference (24/07/2015). To do this, I used the R based Twitter client ‘twitteR’ to access the Twitter API. The resulting data amounted to:
| Total number | |
| Tweets | 671 |
| Retweets | 1025 |
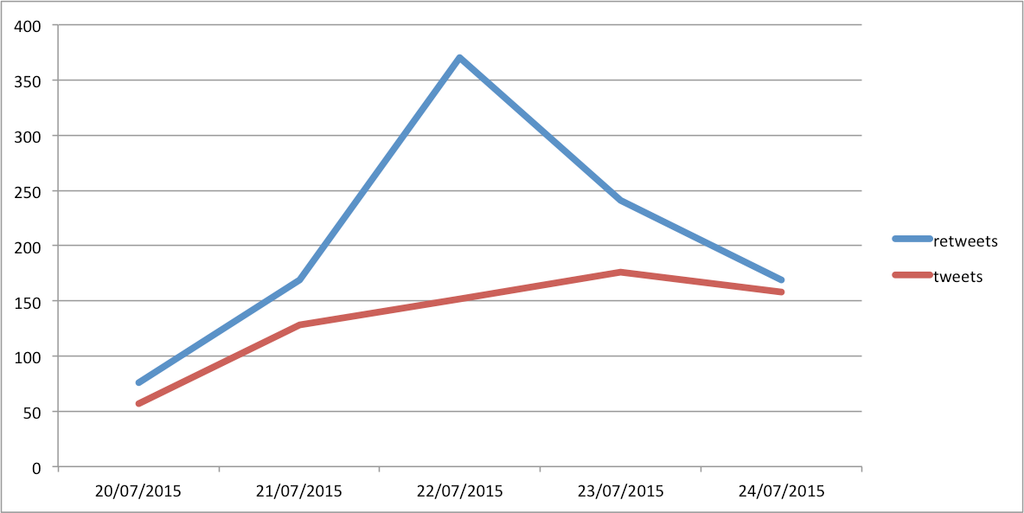
| Tweets | Retweets | |
| 20/07/2015 | 57 | 76 |
| 21/07/2015 | 128 | 169 |
| 22/07/2015 | 152 | 370 |
| 23/07/2015 | 176 | 241 |
| 24/07/2015 | 158 | 169 |
| Totals | 671 | 1025 |
The tweets corpus contained around ~10,000 words in total.
Issues
The data contained some ‘noise’ mainly caused by other people using the same #CL2015 hashtag to talk about another event occurring during the period of the conference. However, as I will show in the analysis, the methods enable researchers to focus only on the communities they are interested in.
Analysis
Tweets – what was being talked about?
To find out what people were talking about day-to-day, I created daily tweet corpora. With each of these daily corpora, I performed a keyword analysis using a reference corpus compiled using the remaining other days. So, for the tweets sent during the pre-conference workshop day (20/07/2015) I used the tweets sent during the rest of the conference (21/07/2015-24/07/2015) as a reference corpus, and so on. The resulting top 10 keywords for each day are given in the table below.
| 20/07/2015 | 21/07/2015 | 22/07/2015 | 23/07/2015 | 24/07/2015 | |
| 1 | CL2015 | change | sealey | partington | illness |
| 2 | workshop | fireant | granger | duguid | mental |
| 3 | pre | biber | animals | gala | news |
| 4 | workshops | climate | sylviane | class | literature |
| 5 | conference | doom | campaign | dinner | yahoo |
| 6 | main | misogyny | heforshe | please | dickens |
| 7 | starting | academic | collocation | poster | csr |
| 8 | historian | assist | eeg | legal | health |
| 9 | day | biber’s | handford | alan | incelli |
| 10 | lancaster | bnc | learner | mock | jaworska |
The keywords shown in each column outline the most distinctive topics tweeted about during the conference. Italics used here relate back to keywords in the table.
On day 1, the pre-conference workshops, including @antlab‘s pre-conference corpus tools brainstorming session and @stgries’s pre-conference #R workshop were popular topics of conversation in the smallest subsample of tweets for the week.
Top favourited tweet from day 1:
Conclusion from this morning's discussion – we need an R for Corpus Linguistics MOOC #cl2015
— Charlotte Taylor (@_ctaylor_) July 20, 2015
On day 2, more diverse topics start to emerge. Change became a theme, relating to Andrew Salway’s talk on discourse surrounding climate change but also relates to a talk given by Doug Biber on historical linguistic change in ‘uptight’ academic texts. Fireant, a new user-friendly tool for efficiently dealing with large databases developed by Laurence Anthony, was also unveiled to the CL masses on day 2, which prompted a flurry of excited tweets [keep track of Laruence’s Twitter page for release]. DOOM and misogyny also became topical following talks by Claire Hardaker and Mark McGlashan on the Discourse of Online Misogyny project. Finally, some excitement followed a paper given by Robbie Love and Claire Dembry about the new Spoken BNC2014. For those interested, keep track of the CASS website for spoken data grants later in the year.
Top favourited tweet from day 2:
https://twitter.com/_paulbaker_/status/623497447915036672/photo/1
Day 3 saw another topic change focussing most prominently on Alison Sealey’s talk on the discursive construction of animals in the media, Sylviane Granger’s plenary on learner corpora, a talk on the public’s online reactin to the #HeForShe campaign given by Rosie Knight, and Jen Hughes’ talk on the application of EEG (‘Electroencephalography’) to the study of collocation as a cognitive phenomenon.
Top favourited tweet from day 3:
https://twitter.com/WatchedPotts/status/623868546427297792/photo/1
After 3 days of incredibly interesting talks, corpus linguists were about ready for their gala dinner on day 4. But before all the cheesecake, the CL2015 were excitedly tweeting about the all important poster session, Alison Duguid’s talk on class, the Geoffrey Leech tribute panel which included Charlotte Taylor’s paper on mock politeness and ‘bitchiness’ as well as Lynne Murphy and Rachele de Felice’s talk on the differential use of please in BrE and AmE, Alan Partington’s plenary speech on CADS; and papers given by Ruth Breeze, Amanda Potts, and Alex Trklja, on the application of CL methods to the study of a broad range of legal language.
Top favourited tweet from day 4:
To access the new HT semantic tagger from the @SAMUELSProject see http://t.co/5LFWH8YGAH and http://t.co/BPxcC8pNNK #CL2015
— Paul Rayson (@perayson) July 23, 2015
Day 5 brought #CL2015 to a close but the number of tweets remained steady with health on the agenda with talks from Ersilia Incelli and Gillian Smith who both focussed partly on the construction of mental illness/health in the news. News also featured Monika Bednarek’s talk on news discourse and Antonio Fruttaldo’s analysis of news tickers. Other key topics related to Sylvia Jaworska and Anupam Nanda’s paper on the Corpus Linguistic analysis of Corporate Social Responsibility (CSR), Michaela Mahlberg’s work on the literature of Charles Dickens, and discussion of a corpus of Yahoo answers in the week’s penultimate panel on triangulating methodological approaches.
Top favourited tweet from day 5:
It's Friday after 5pm and the conference sessions have all finished. Thanks to everyone for coming!! #CL2015 pic.twitter.com/MBJHrAuwJa
— UCREL NLP Research Centre (@UCREL_NLP) July 24, 2015
Approaching tweets in this way, it was possible to find out the most salient topics of each day. However, I was also interested in the retweeting behaviour of attendees.
Retweets – what was being talked about?
I looked at the top 10 most frequently retweeted tweets during the conference. Due to the intertextual nature of retweets – they are simply identical reposts of the same content – methods familiar to CL such as word frequency lists may not be as useful in their study. For example, if a few retweets are particularly frequently reposted, the most frequent words will be skewed by the content of the most frequent retweets. Instead, I suggest that retweets themselves should be conceptualised as being individual types in and of themselves that require more qualitative approaches to their interpretations (at least in this context). The top 10 most frequently retweeted tweets including the #CL2015 hashtag are given below:
| Retweet | Date | Freq | |
| 1 | RT @EstrategiasEc: Concluimos este viernes con exitoso proceso de postulación @ECLideres VI Prom. #CL2015 con auspicio de @ucatolicagye. ht… | 22/07/2015 | 218 |
| 2 | RT @perayson: To access the new HT semantic tagger from the @SAMUELSProject see http://t.co/5LFWH8YGAH and http://t.co/BPxcC8pNNK #CL2015 | 23/07/2015 | 15 |
| 3 | RT @UCREL_Lancaster: The #CL2015 abstract book is now available to download from the conference website http://t.co/px9hh3mMNe | 21/07/2015 | 13 |
| 4 | RT @duygucandarli: Important take-away messages about corpus research in Biber’s plenary talk at #CL2015! http://t.co/xm87Uo1umZ | 21/07/2015 | 11 |
| 5 | RT @lynneguist: Alan Partington looking at how quickly language changes in White House Press Briefings… #CL2015 http://t.co/jeVjvC8Ym3 | 23/07/2015 | 10 |
| 6 | RT @CorpusSocialSci: .@_paulbaker_ reflecting on a number of approaches to the same data at the Triangulation panel at #CL2015 http://t.co/… | 24/07/2015 | 10 |
| 7 | RT @CorpusSocialSci: .@vaclavbrezina introduces Graphcoll, a new visualisation tool for collocational networks #CL2015 http://t.co/PM5FxS5N… | 22/07/2015 | 9 |
| 8 | RT @_ctaylor_: It’s a myth that reference corpora have to larger than target corpus says @antlabjp #cl2015 | 22/07/2015 | 7 |
| 9 | RT @Loopy63: #CL2015 Call for papers for Intl. Conference on statistical analysis of textual data 2016 in Nice, France: http://t.co/3JpcAa… | 23/07/2015 | 7 |
| 10 | RT @vaclavbrezina: A great use of #GraphColl by @violawiegand – #CL2015 poster presentation @TonyMcEnery @StephenWattam http://t.co/uwlMGUY… | 24/07/2015 | 7 |
The most frequent retweet was regarding a Latin American Youth Leadership programme that shared the same #CL2015 hashtag [nb. For next year, Corpus Linguistics conference organisers…]. As you will notice, this retweet occurred on 22/07/2015 but as retweets and tweets are dealt with exclusively, the retweet does not interfere with the keyword analysis done for the same day on the tweets.
What do the most frequent retweets highlight? Free tools (GraphColl, HT semantic tagger), free resources (abstract book), plenary talks and more conferences.
Networks
With a general idea of what people are talking about and sharing using the #CL2015 hashtag, I was interested to examine the overall activity around #CL2015 and the emergence of discourse communities.
In terms of tweets the gif below shows how relationships developed over the course of the conference. Every node represents a Twitter account that posted a tweet containing #CL2015 during the period of data collection. The size of these nodes is dictated by their ‘degree’, or its number of edges. More edges = larger node. The colour of the nodes is determined by ‘betweenness centrality’, which indicates how central a node is in a network. Nodes with high betweenness centrality help the speed of transfer of information through networks as they help create the shortest distance between other nodes in the network. Nodes with high betweenness centrality are coloured red, a medium betweenness centrality is yellow, and low betweenness centrality is blue. Nodes with intermediary colours (orange, green) represent those that have a betweenness centrality somewhere between low and medium or between medium and high. Finally, the colour and size of edges is dictated by ‘weight’. In this example, weight is dictated by the frequency of tweets that exist between nodes. Thick red edges between nodes represent nodes that send tweets to each other frequently, or one node mentions another frequently. Thin blue edges represent low frequency mentioning relationships. Yellow are medium. Again, blended colours represent intermediary frequencies and thus, in this case, weight.
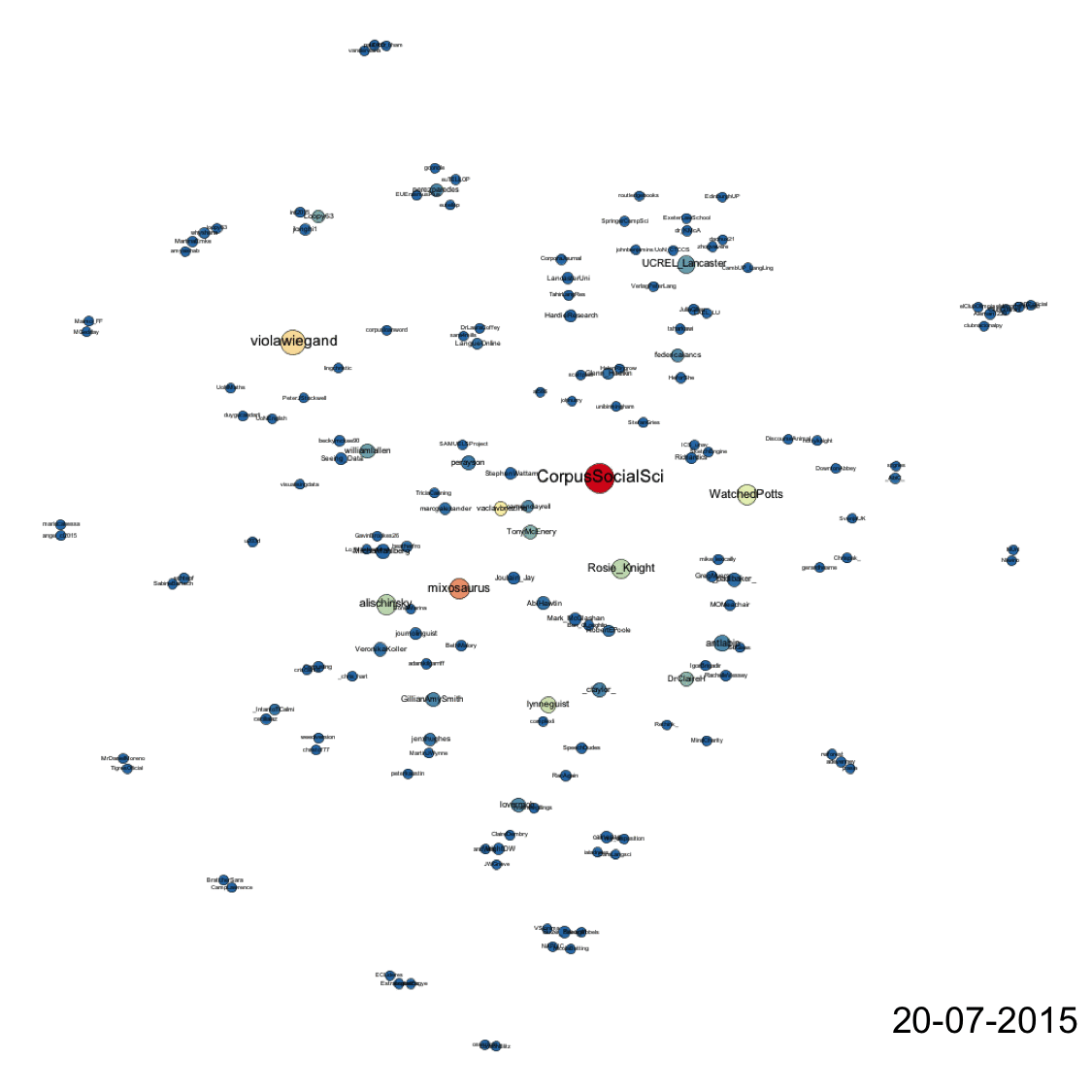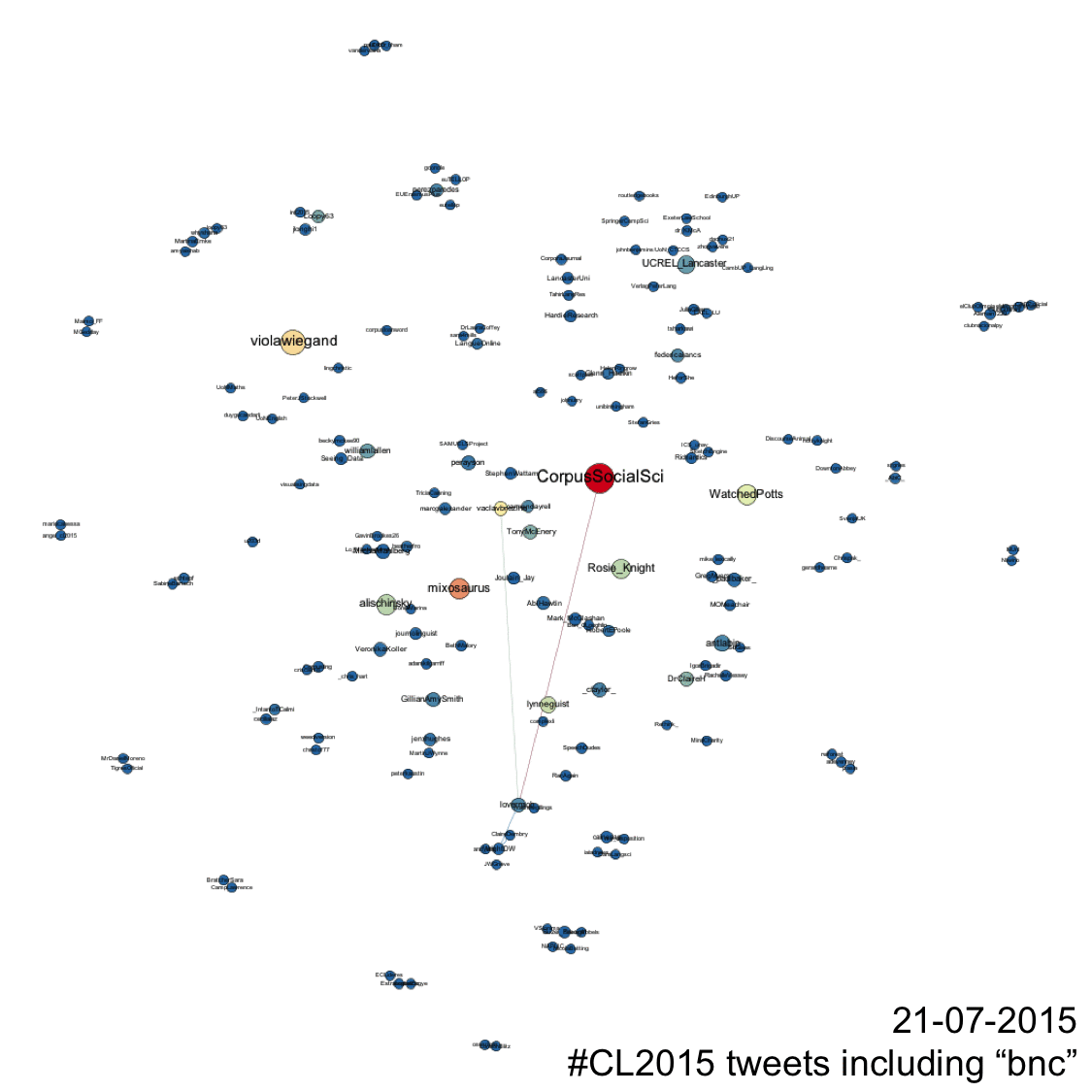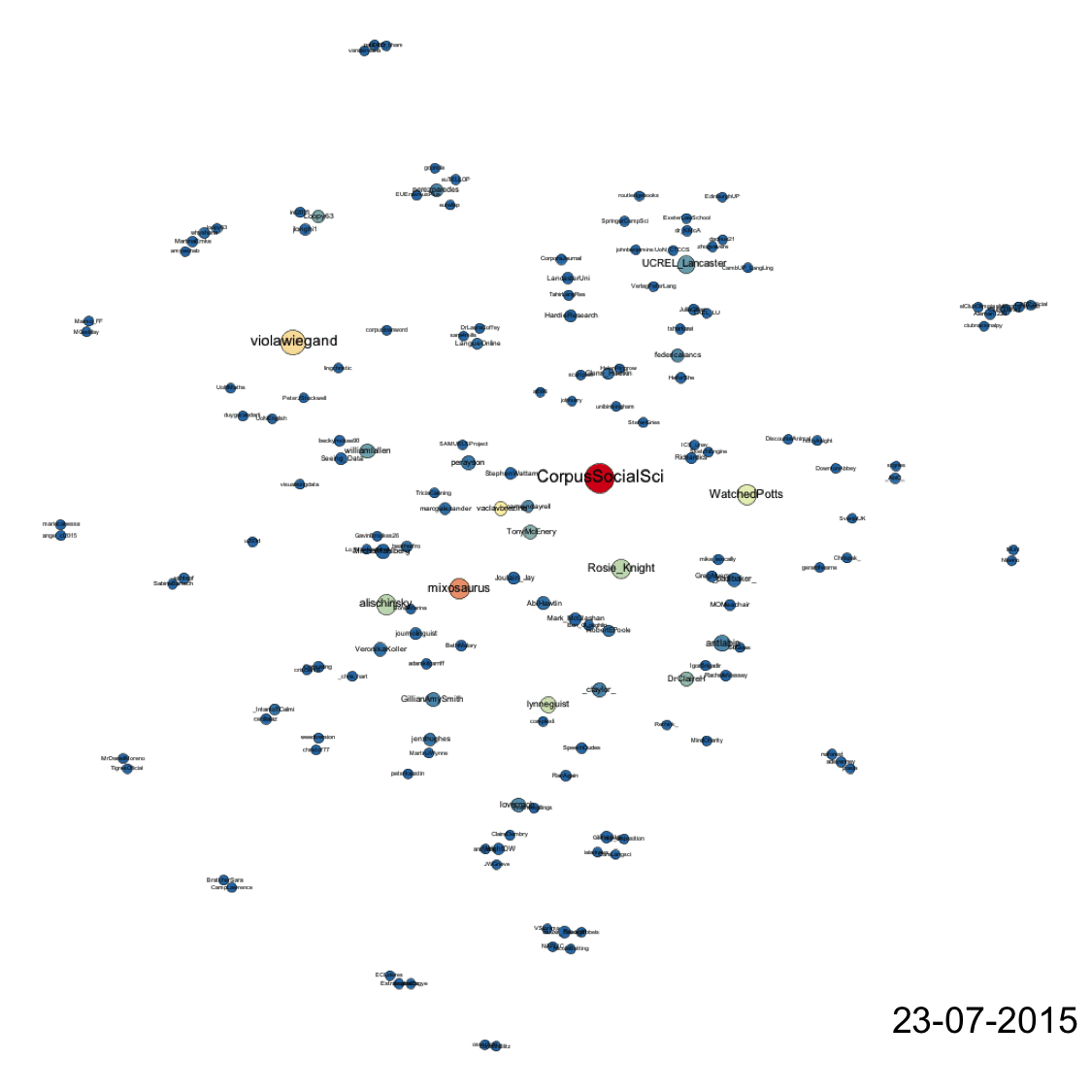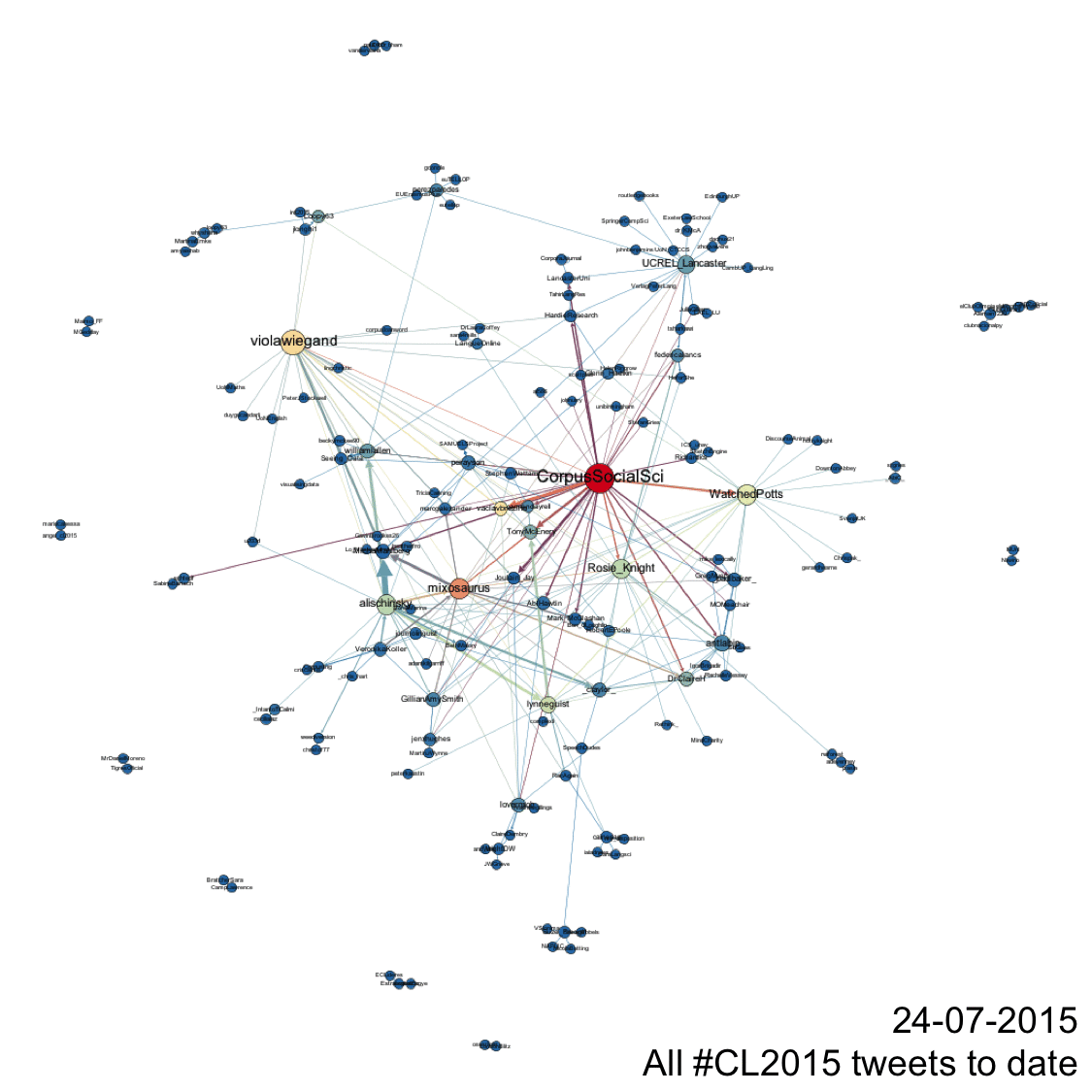
The tweets network shows that @CorpusSocialSci was – perhaps unsurprisingly – the most prolific and central account in the #CL2015 network. It had the most connections and joined the most individual accounts together. But other users were very active in helping to disseminate information more widely, which are shown by those nodes in yellow and orange. The accounts on the periphery of the network are good examples of ambient affiliation. They use #CL2015 to affiliate but do not directly engage with others by mentioning other users. Moreover, the gif attempts to show the evolution and growth of the network over time but also shows that each day new topics and networks of interaction relating to those new topics emerged daily. As talks (and news of talks in the network) became topical, people tweeted and shared ideas and notes relevant to those talks. An example of this is the emergence of fireant on 21/07/2015. When introduced to delegates, an ad hoc online discourse community formed to spread the news of a new tool, add new information and to channel their enthusiasm back to source.
| User | Date | Tweet |
| RachelleVessey | 2015-07-21 16:50:43 | Excellent end to the first day of #CL2015- FireAnt looks like a fantastic programme @antlabjp @DrClaireH can’t wait to try it out! |
| SLGlaas | 2015-07-21 16:54:13 | Stupidly excited about #Fireant from @antlabjp #CL2015 |
| CorpusSocialSci | 2015-07-21 16:54:43 | Everyone is eagerly wondering when FireAnt will be available. @antlabjp’s answer is hopefully within the next few months. #CL2015 |
| Rosie_Knight | 2015-07-21 16:56:40 | Amazing talk about FireAnt- can’t wait to use this on my #HeForShe data! @DrClaireH @antlabjp @Mark_McGlashan #CL2015 |

The retweets network again shows that @CorpusSocialSci was – and, again perhaps unsurprisingly – at the centre of #CL2015 retweeting activity. The retweet network gif shows 2 discrete networks. The right hand network shows activity at the CL conference, the left hand network shows the retweeting behaviour of the Latin American Youth Leadership programme mentioned above. Avid conference tweeters may have noticed when keeping track of the #CL2015 hashtag. The left hand network – a graphic representation of the most retweeted tweet containing #CL2015 shown above – shows 218 users retweeting a single central account. In this network there is no interaction between the users engaged in retweeting this user. This kind of network formation is extremely typical of users retweeting news stories on Twitter. The right hand network, however, shows a great deal of mutual retweeting, whereby users are engaged on a prolonged basis in sharing each others’ tweets and forming a network of sharing and resharing.
Summary
Integrating methods from CL and SNA offers some really interesting possibilities for the analysis of large amounts of social data. Here, I have used keyword analysis to find the most salient topics for each day of the conference, used those topics to find and visualise small but coherent discourse communities, and situated those communities within the wider #CL2015 social network.
Contact
References
Baker, P. (2006) Using Corpora in Discourse Analysis. London: Continuum.
D’Andrea, A., Ferri, F. & Grifoni, P. (2010). An overview of methods for virtual social network analysis. In: A. Abraham, A.-E. Hassanien, & V. Sná el (eds.). Computational Social Network Analysis. London: Springer London, pp. 3–26.
Elgesem, D. & Salway, A. (2015) Traitor, whistleblower or hero? Moral evaluations of the Snowden affair in the blogosphere. In Formato, F. & Hardie, A. (Eds.) Corpus Linguistics 2015 Abstract Book. Paper presented at Corpus Linguistics 2015, Lancaster. Lancaster University. pp 99-101
Foucault, M. (1972) The Archaeology of Knowledge. London: Tavistock.
Grieve, J., Nini, A., Guo, D, & Kasakoff, A. (2015) Recent changes in word formation strategies in American social media. In Formato, F. & Hardie, A. (Eds.) Corpus Linguistics 2015 Abstract Book. Paper presented at Corpus Linguistics 2015, Lancaster. Lancaster University. pp 140-3
Knight, R. (2015) Tweet all about it: public views on the UN’s HeForShe campaign. In Formato, F. & Hardie, A. (Eds.) Corpus Linguistics 2015 Abstract Book. Paper presented at Corpus Linguistics 2015, Lancaster. Lancaster University. pp 201-3
Longhi, J. & Wigham, C. R. (2015) Structuring a CMC corpus of political tweets in TEI: corpus features, ethics and workflow. In Formato, F. & Hardie, A. (Eds.) Corpus Linguistics 2015 Abstract Book. Paper presented at Corpus Linguistics 2015, Lancaster. Lancaster University. pp. 408-9
Hardaker, C. & McGlashan, M. (2015) Twitter rape threats and the discourse of online misogyny (DOOM): from discourses to networks. In Formato, F. & Hardie, A. (Eds.) Corpus Linguistics 2015 Abstract Book. Paper presented at Corpus Linguistics 2015, Lancaster. Lancaster University. pp. 154-6
McGlashan, M. & Hardaker, C. (2015) Twitter rape threats and the discourse of online misogyny (DOOM): using corpus-assisted community analysis (COCOA) to detect abusive online discourse communities. In Formato, F. & Hardie, A. (Eds.) Corpus Linguistics 2015 Abstract Book. Paper presented at Corpus Linguistics 2015, Lancaster. Lancaster University. pp. 234-5
Page, R. (2012). The linguistics of self-branding and micro-celebrity in Twitter: The role of hashtags. Discourse & Communication. 6 (2). p.pp. 181–201.
Scott, J. (2013). Social Network Analysis. 3rd Ed. London: Sage.
Statache, R., Adolphs, S., Carter, C. J., Koene, A., McAuley, D., O’Malley, C., Perez, E. & Rodden, T. (2015) Descriptive ethics on social media from the perspective of ideology as defined within systemic functional linguistics. In Formato, F. & Hardie, A. (Eds.) Corpus Linguistics 2015 Abstract Book. Paper presented at Corpus Linguistics 2015, Lancaster. Lancaster University. p. 433
Zappavigna, M. (2012). Discourse of Twitter and social media. London: Continuum.
Zappavigna, M. (2013). Enacting identity in microblogging through ambient affiliation. Discourse & Communication. 8 (2). pp. 209–228.